1. Intro to Computer Vision
Part of CS231n Winter 2016
Lecture 1: Introduction and Historical Context¶
Fei-Fei Li opens the course by describing computer vision as the "dark matter of the internet": vast, ubiquitous imagery that still defies full understanding.
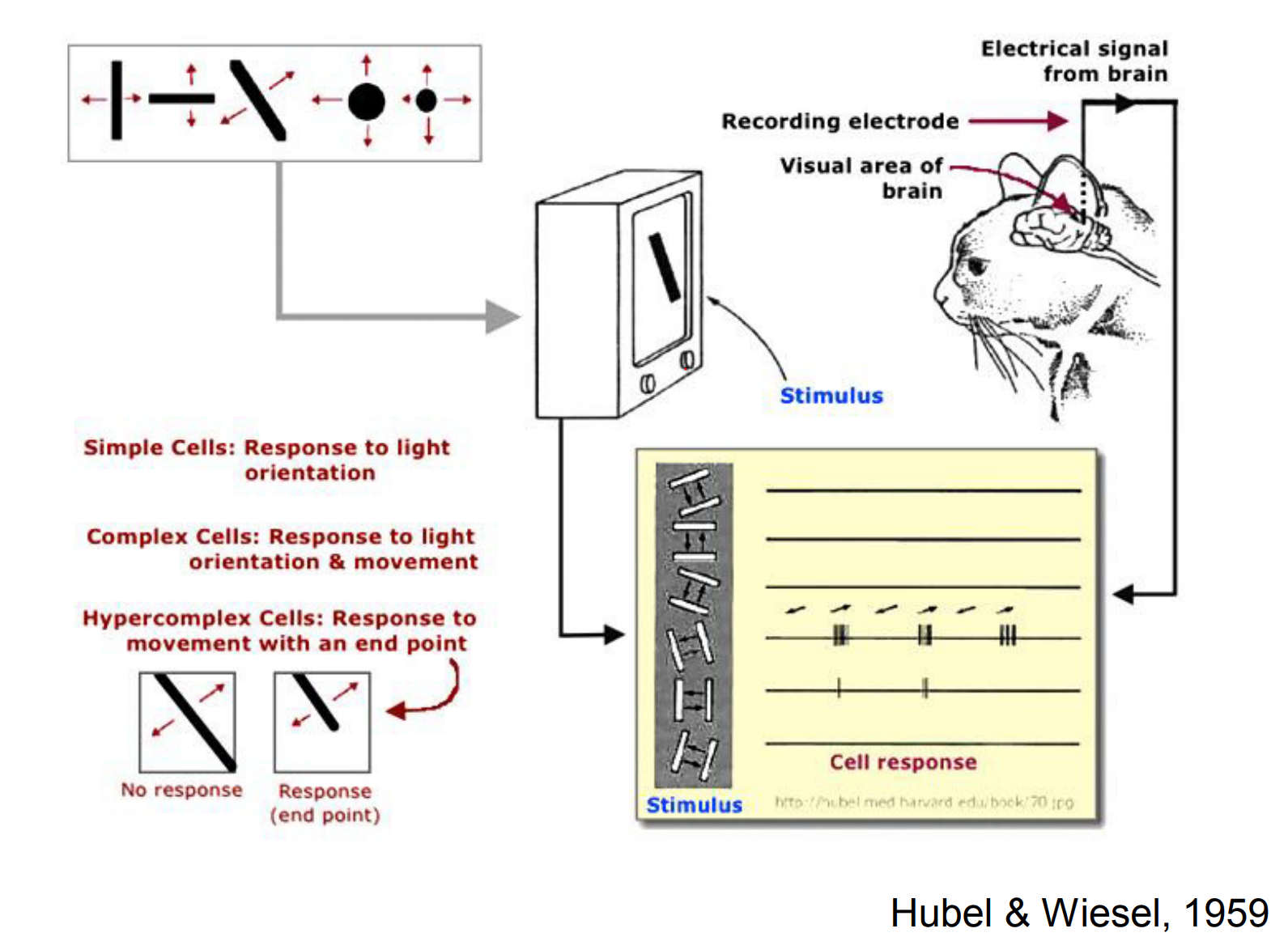
Humans devote enormous brain capacity to sight, and even subtle transitions between slides trigger neural responses across the visual cortex (see Hubel & Wiesel Experiments).

She traces the story from Aristotle's camera obscura ideas, through Leonardo da Vinci's detailed sketches, to Larry Roberts's early attempts at extracting edge structures from images.

The 1966 MIT Summer Vision Project promised a quick solution to perception but instead exposed how complex vision really is.
Vision is so easy LOL!
As you can imagine, Computer Vision was not solved in that Summer.

Researchers realized that perception must be hierarchical. Hubel and Wiesel urged starting from simple stimuli, while David Marr advocated layered models that connect raw signals to higher-level understanding.

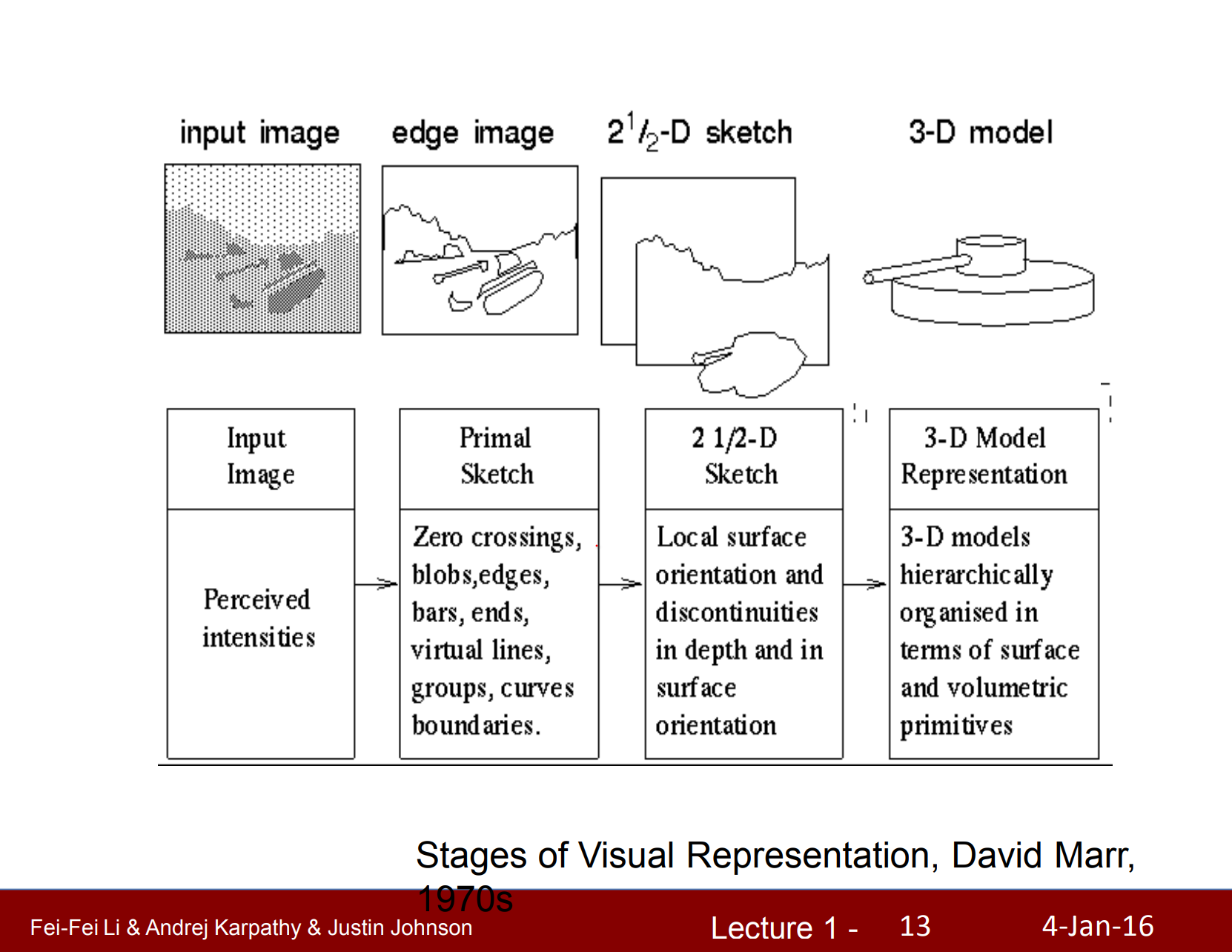
The world is three-dimensional even though retinal images are two-dimensional. We rely on both hardware tricks (our two eyes) and software tricks (inference and learning) to recover structure.
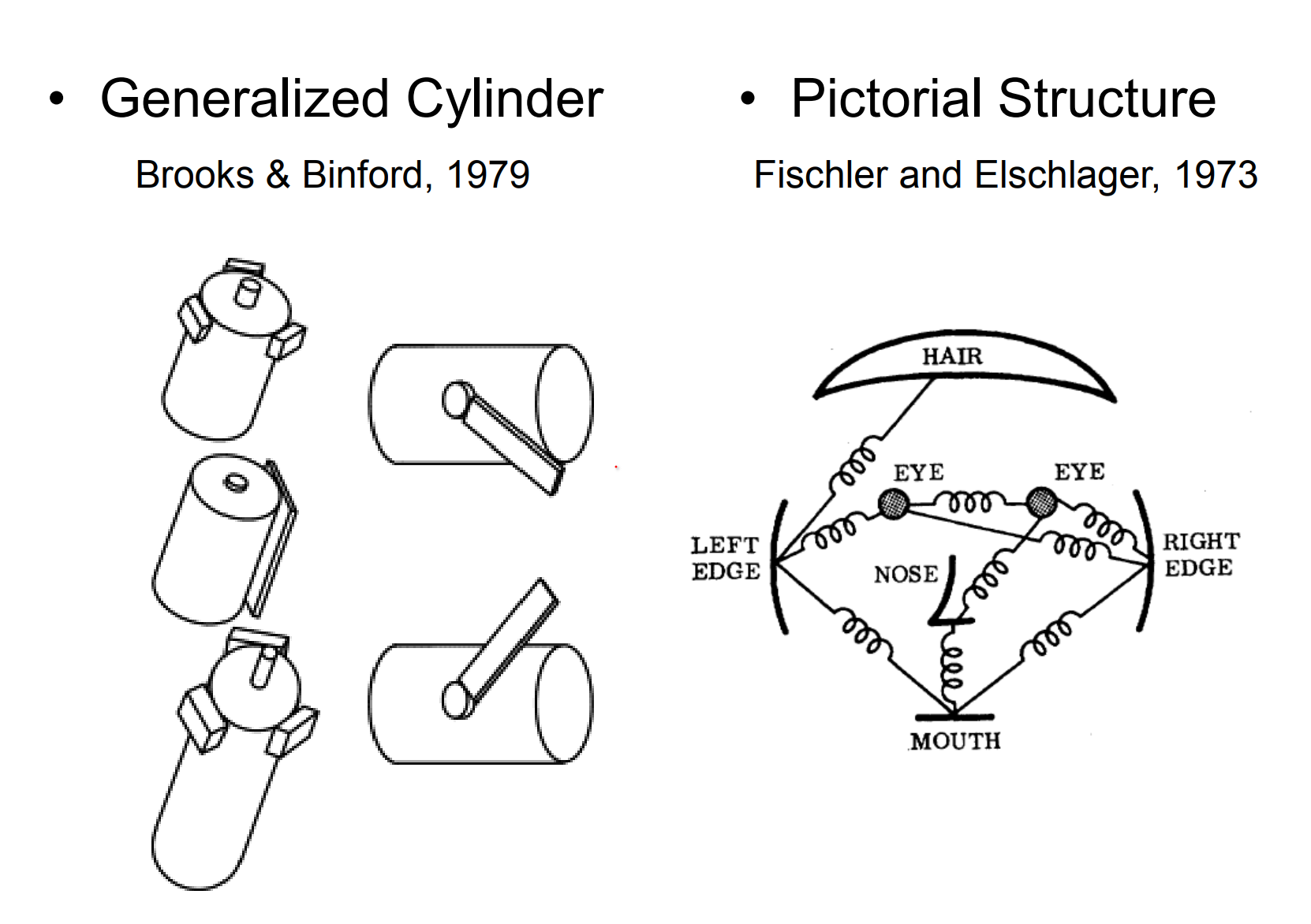
Brooks - (Founder of MIT AI Lab - Founder of Roomba ) - World is combined of simple shapes.
Fischler - Parts are connected by strings (not everyone has the same eye distance between). Not everyone sees the world as the same.
From Grouping to Features¶
Perceptual grouping lets us walk into a room and immediately organize the scene instead of drowning in pixels.

That intuition powered one of the first practical real-time systems from Viola and Jones, whose cascade of features became a milestone for color imagery and face detection.

This work (Viola&Jones) was the first paper Fei Fei Li read when she was working as a graduate student.
Their ideas soon shipped inside Fujifilm's first smart digital camera with a built-in face detector, showing how research could influence consumer hardware.
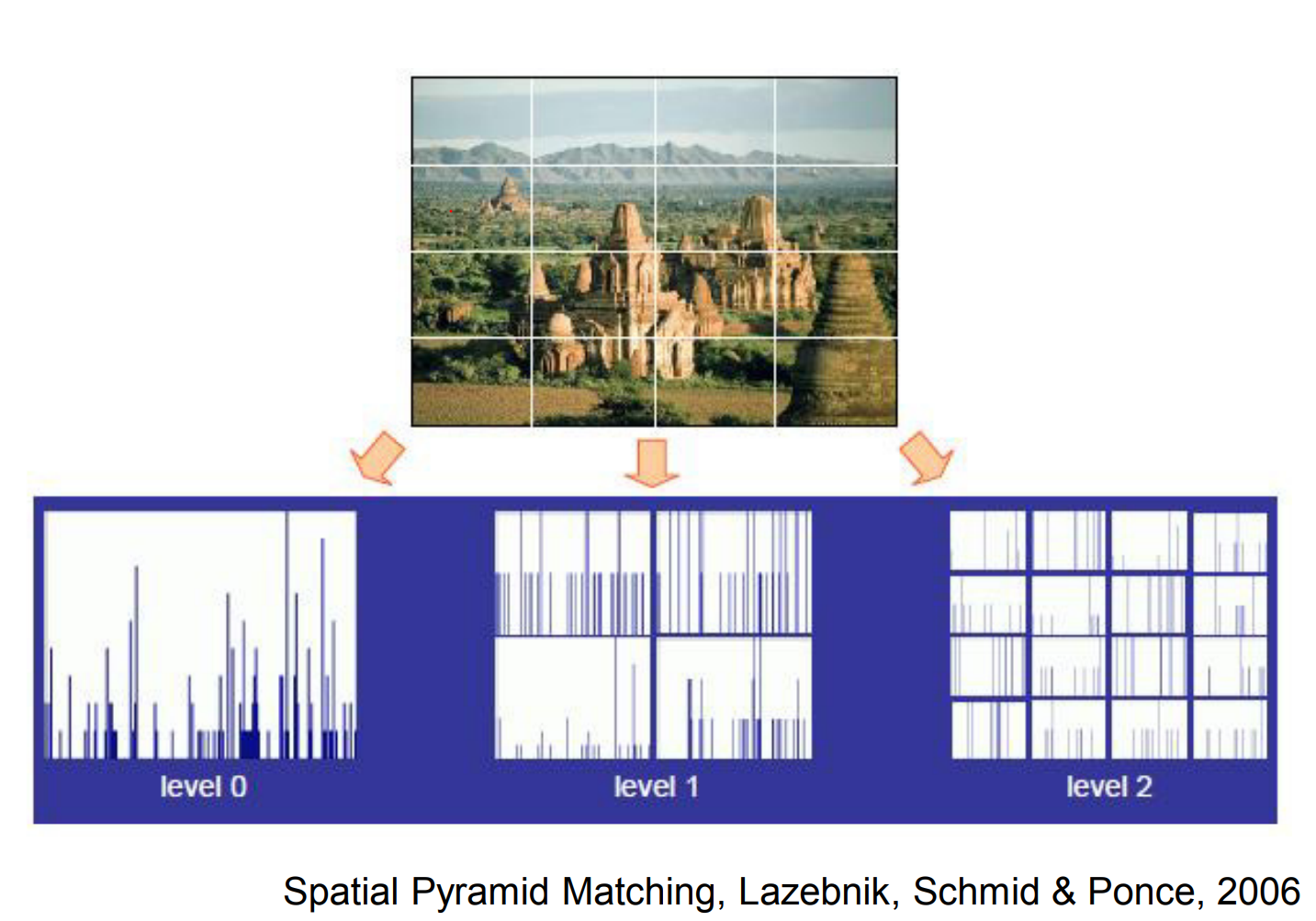
Recognizing objects from whole images proved difficult, so the community focused on describing informative local features.
SIFT, HOG, and related descriptors handled occlusion and clutter by capturing stable parts of objects.
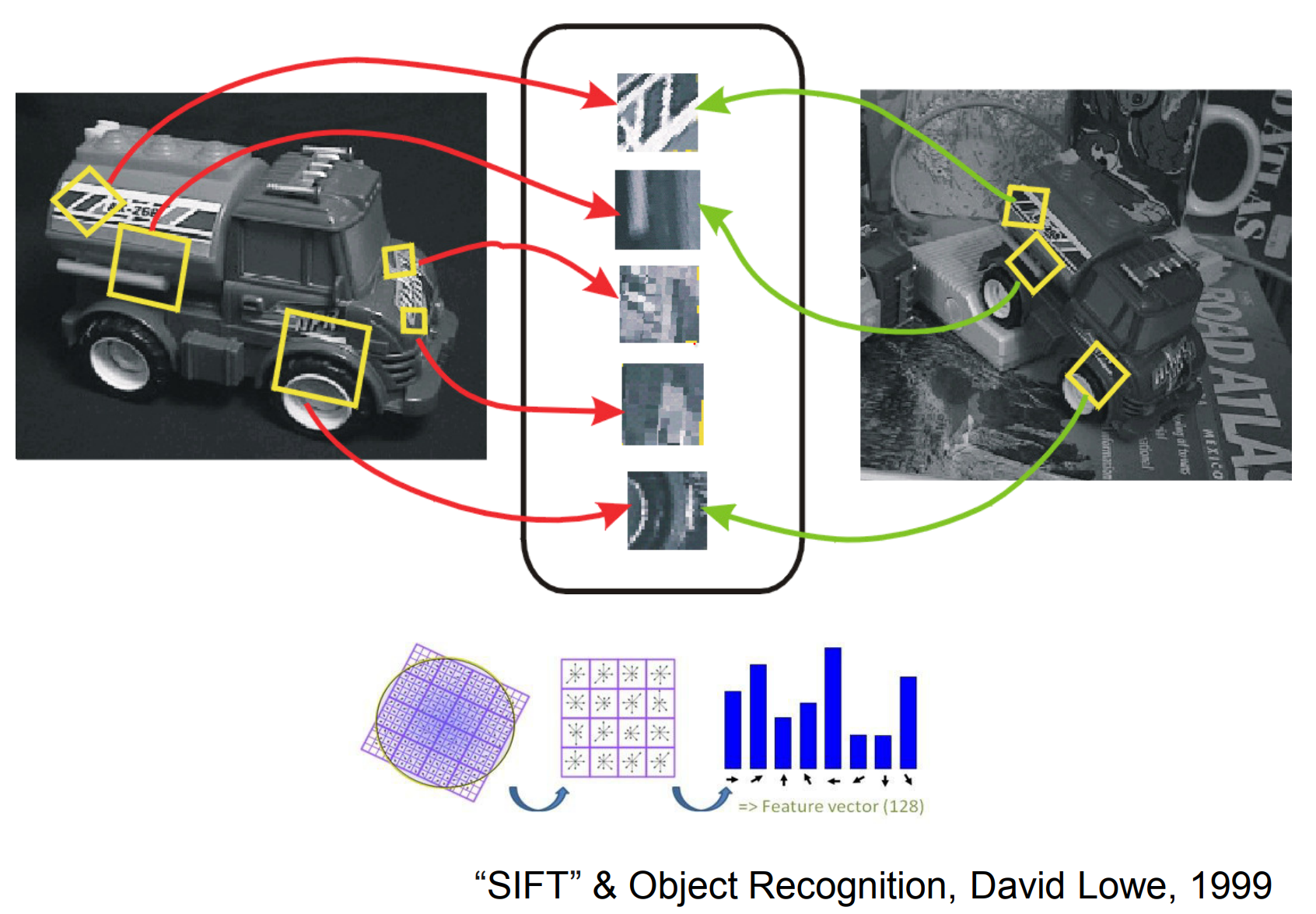
I see you guys, heavily occluded. I don't see the rest of your torso, I don't see your legs. But I can recognize you.
So people started to think about features in recognition.
So SIFT is all about learning important features of an object. If we can do that, we can recognize the object on different angle in a cluttered scene.
From 2000 to 2010 entire field of CV was just focusing on features.
One of the reasons Deep Learning became more convincing to a lot of people is that, a DL network learns really similar features very similar to these engineered features (like on SIFT).
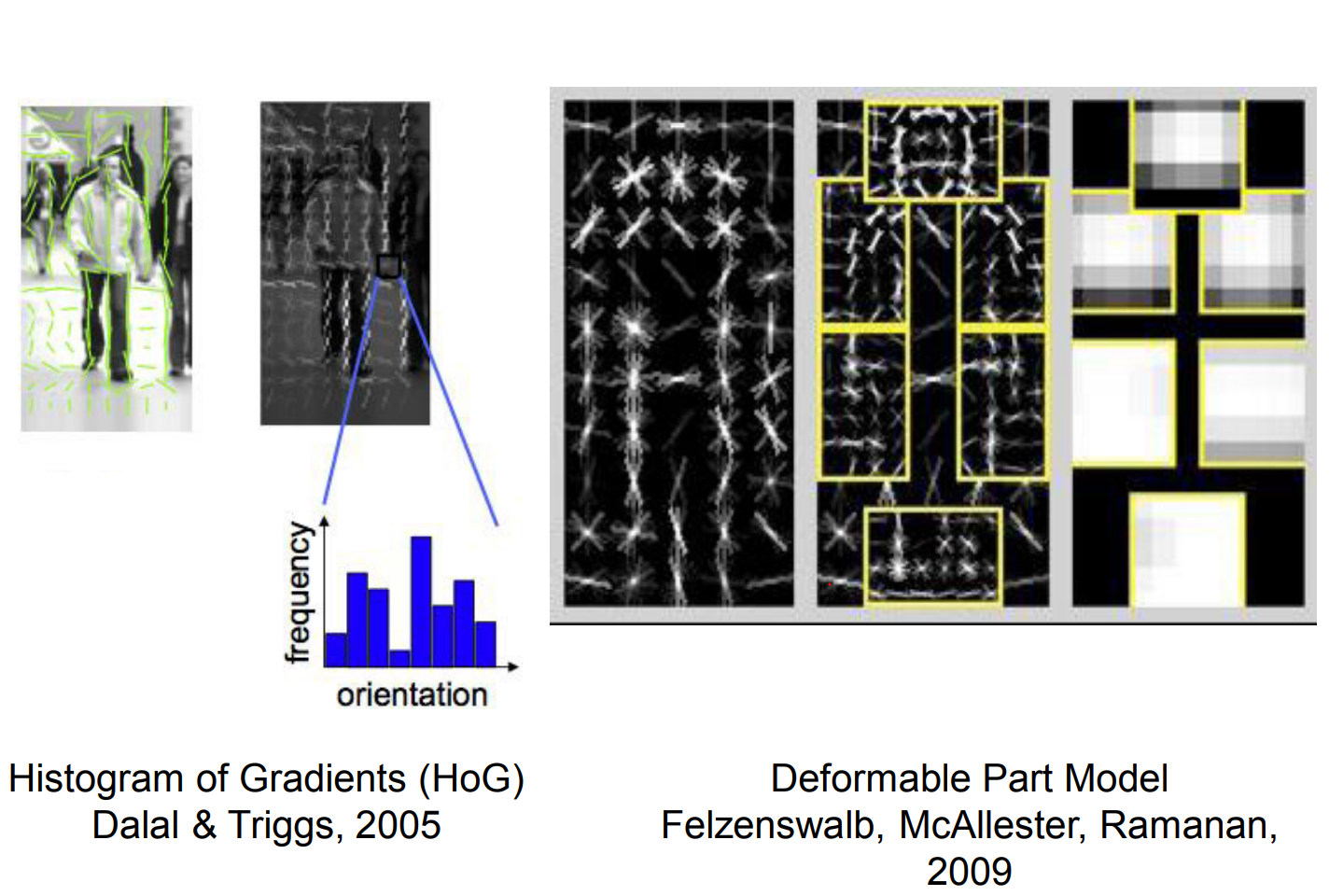
By the late 2000s, deformable part models extended this thinking to demanding tasks such as pedestrian detection.
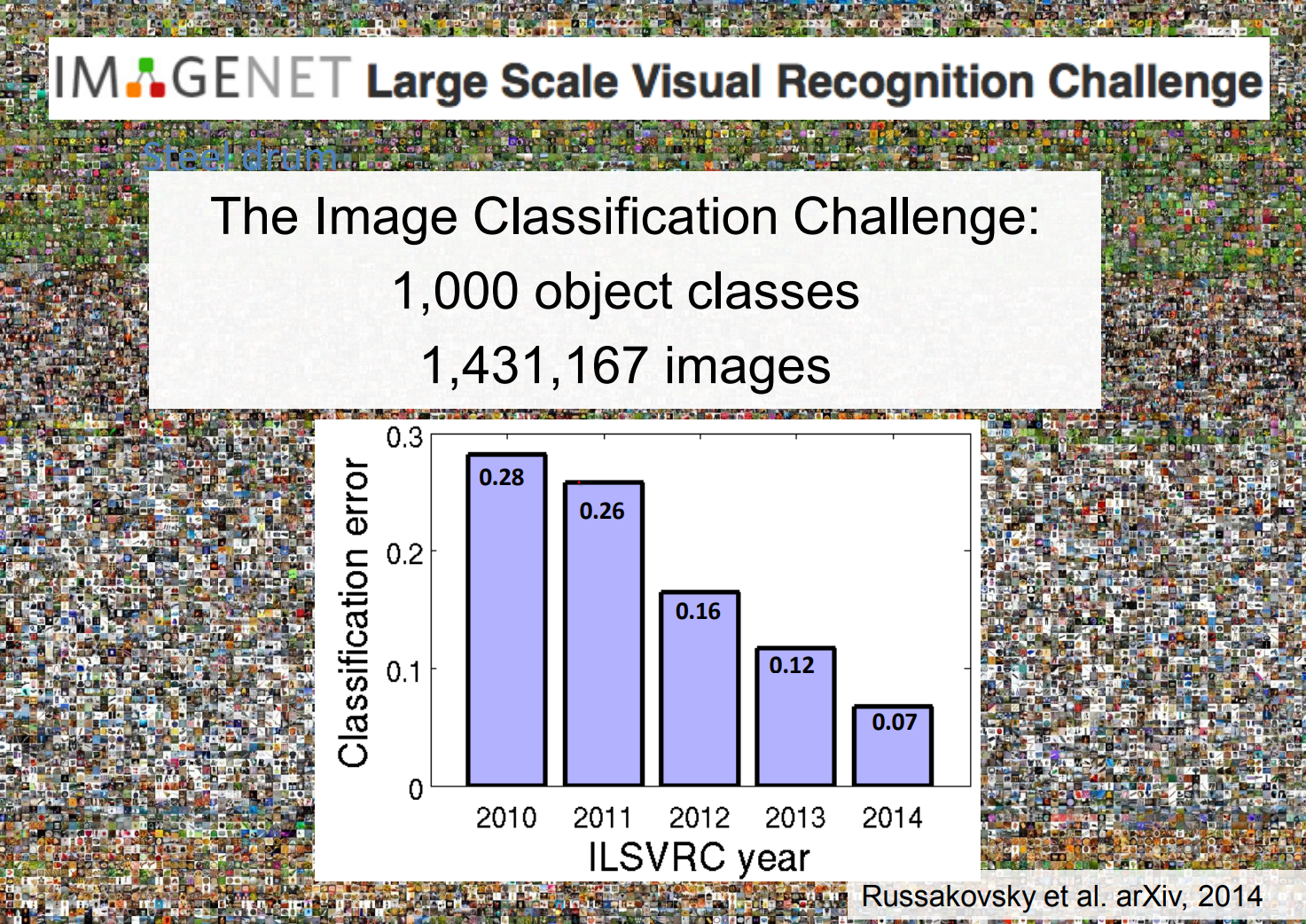
PASCAL VOC and ImageNet¶
Competitions needed strong benchmarks, which led to the PASCAL VOC challenge and its 20 carefully labeled categories.
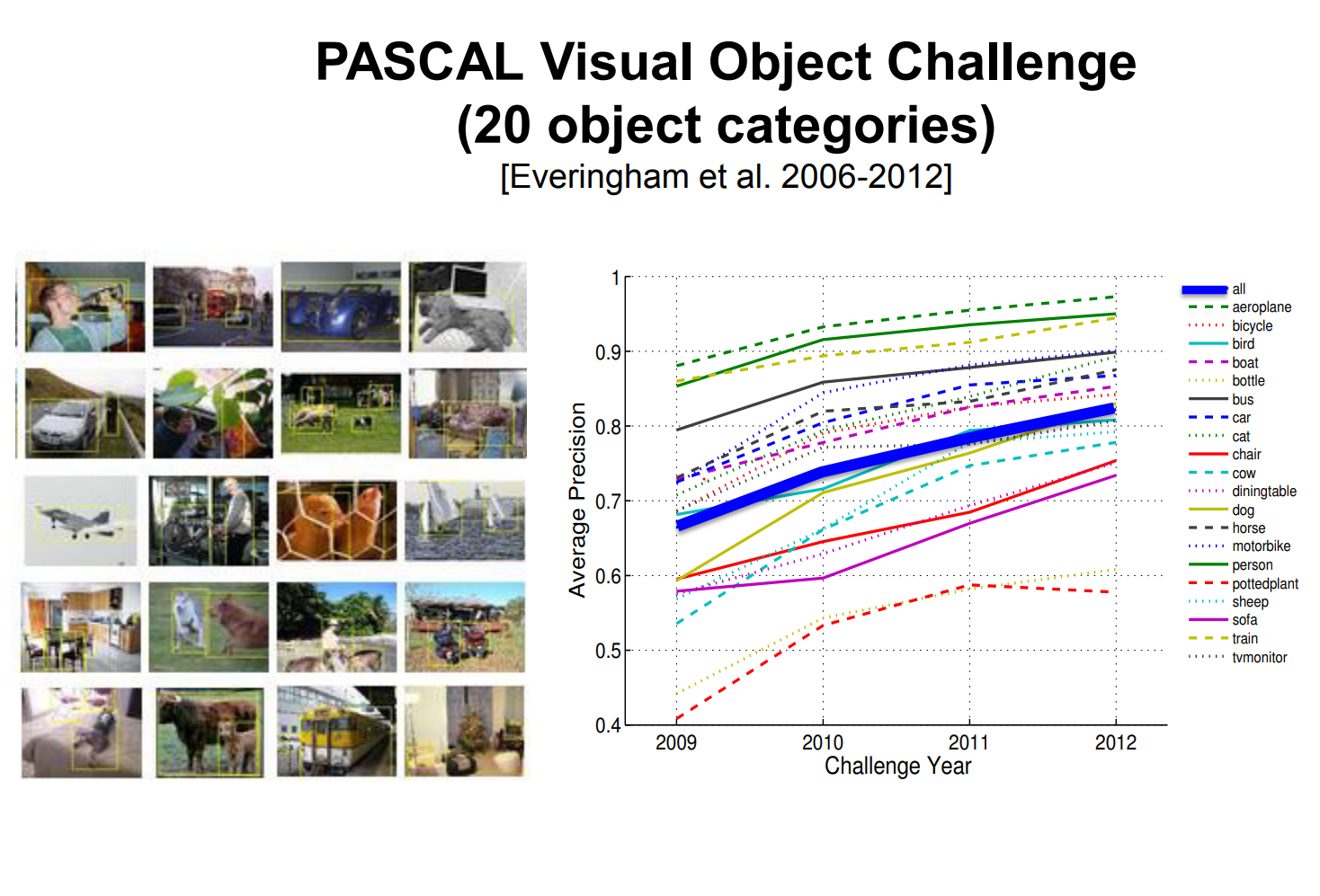
Fei-Fei Li and her students wanted to capture more of the visual world, so they launched ImageNet and an annual recognition challenge that pushed the scale far beyond those 20 classes.

Some called this the olympics of Computer Vision!

Every year error decreased.
The Deep Learning Shift¶
ImageNet supplied the massive labeled dataset that deep learning craved. Error rates dropped each year until AlexNet's convolutional neural network crushed the 2012 competition, igniting the modern deep learning era.

The lecture highlights how CS231n focuses on image classification while connecting to related problems such as detection and captioning.

Convolutional Networks Resurface¶
Convolutional neural networks were not invented overnight. The neocognitron laid groundwork in 1979, and Yann LeCun's team at Bell Labs built layered networks for zip code recognition that mirrored Hubel and Wiesel's neuroscience insights.
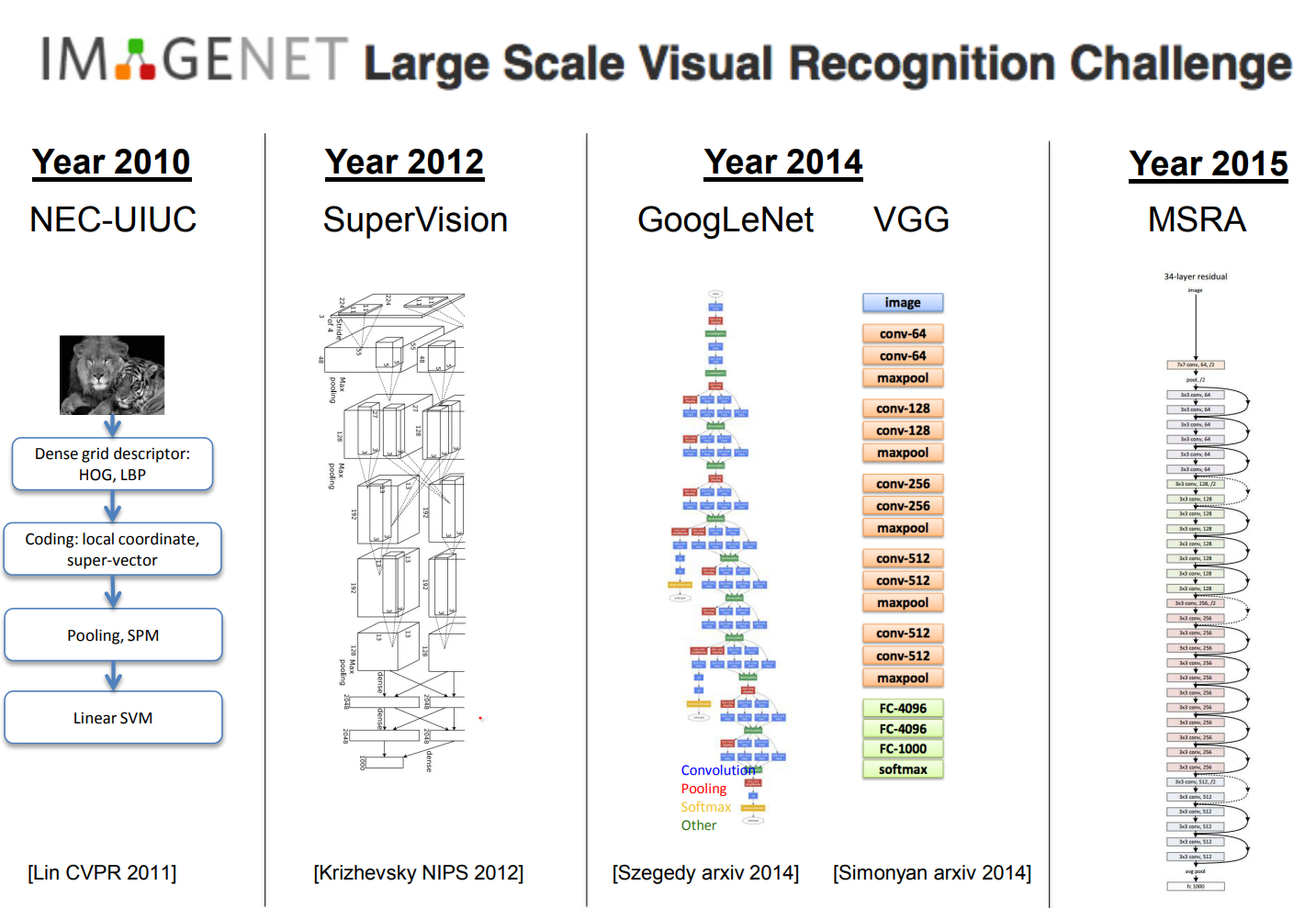
Alex Krizhevsky and Geoffrey Hinton. Here is the paper
Fast forward to 2015 - 151 layered CNN - Microsoft Asia Research Group.
However, Convolutional Neural Network (CNN) is not invented overnight.
The neocognitron is a hierarchical, multilayered artificial neural network proposed by Kunihiko Fukushima in 1979. This was the beginning of NN's.
The groundbreaking work was of the Yann Le Cun's.
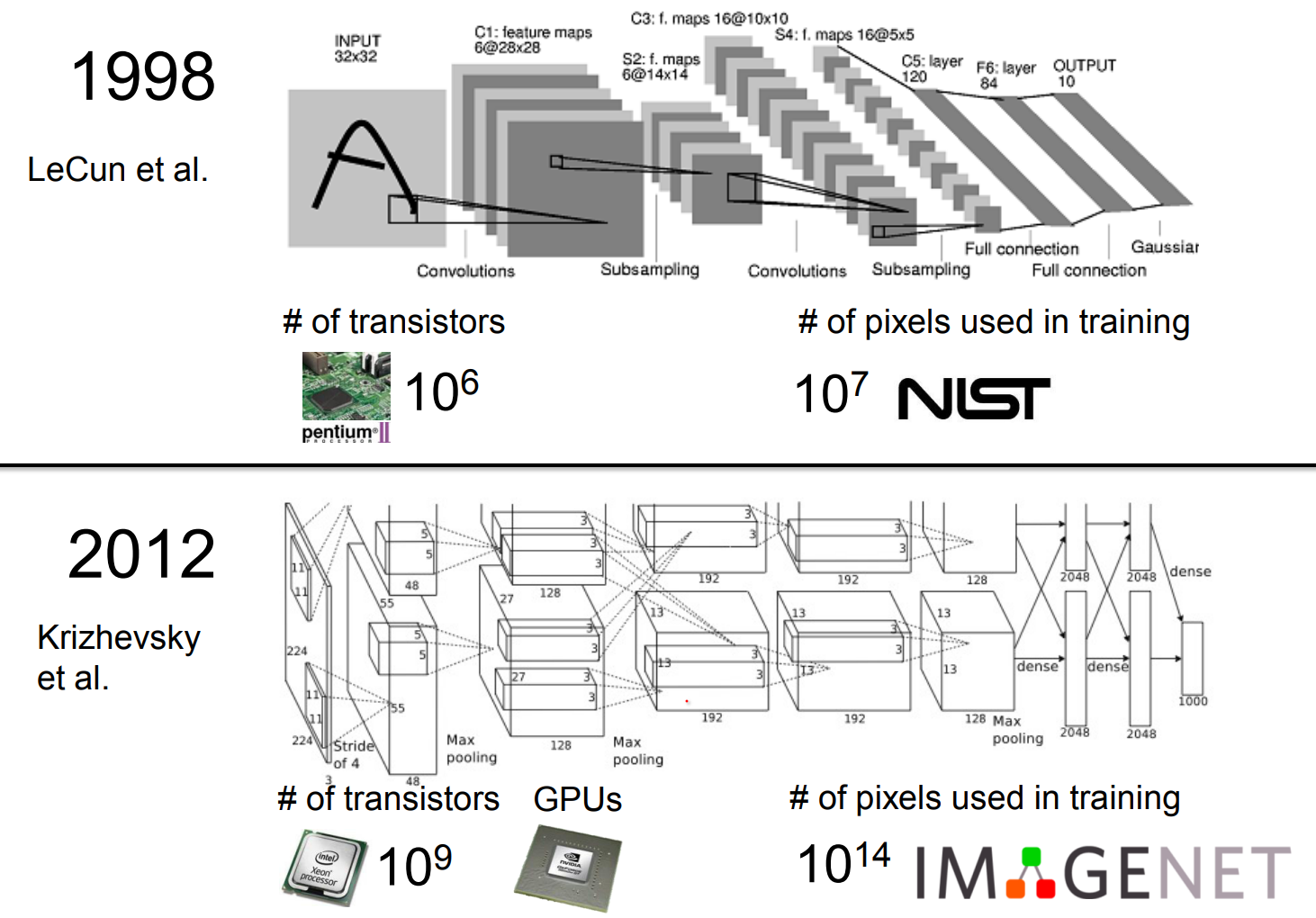
Yann was working in Bell Labs. Amazing place at that time.
He needed to recognize digits, US post office to recognize zip codes.
He was inspired by Hubei and Wiesel.
He starts by looking simple edge like structures, not whole letters.
Layer by layer, he filters this edges and pool em together.
In 2012, almost the same architecture. Sigmoid to rectified linear shape but whatever LOL.
The 2012 breakthrough succeeded because two ingredients changed: - Hardware kept pace with Moore's Law, giving researchers powerful GPUs. - Vast labeled datasets became available, allowing networks to learn rich representations.
Open Problems and Course Philosophy¶
Despite rapid progress, core challenges remain: dense labeling, 3D reasoning, motion understanding, and integrating recognition with broader scene structure.
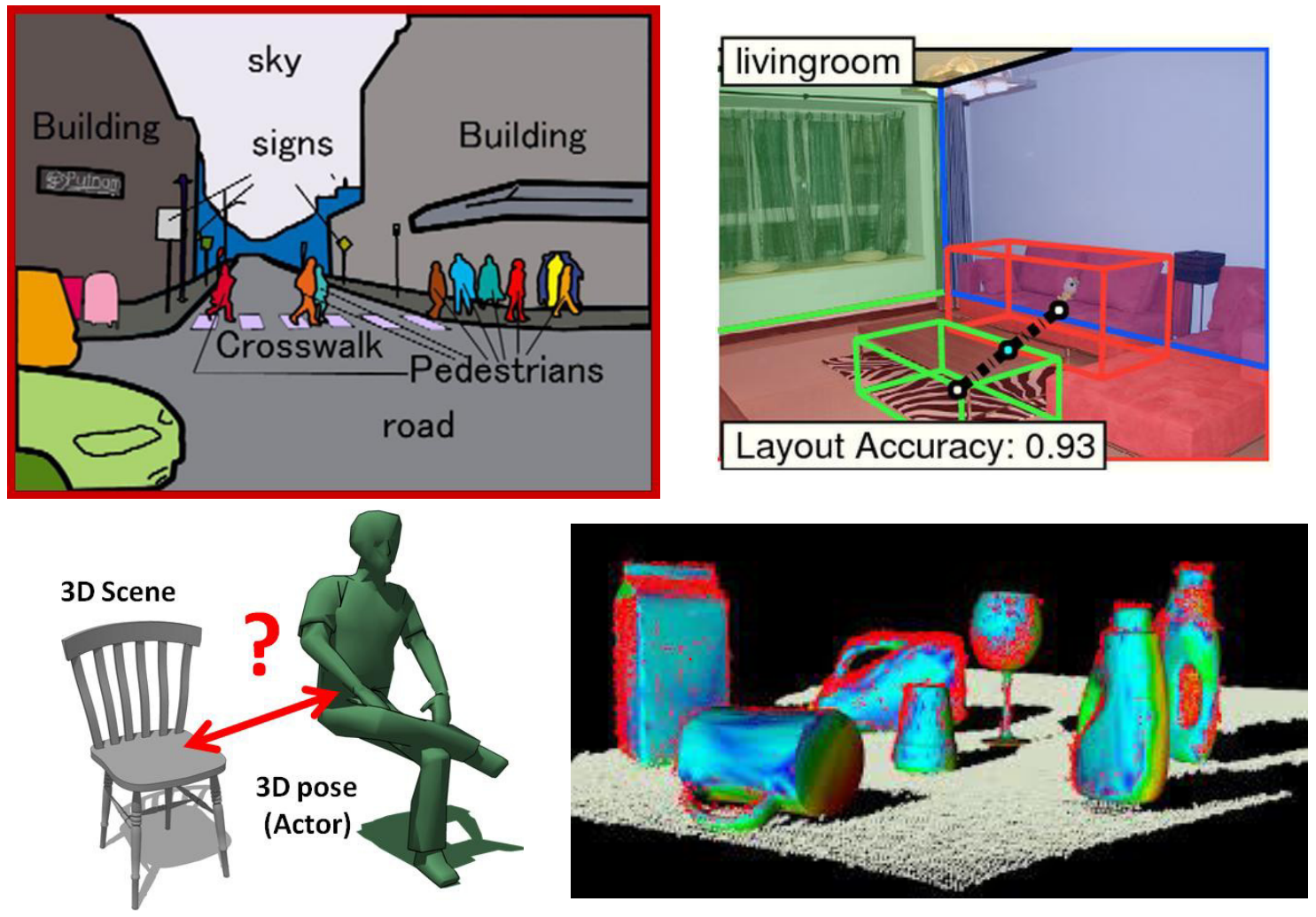
Dense labeling of en entire scene with perceptual grouping. Combining recognition with 3D. Motion and so on..
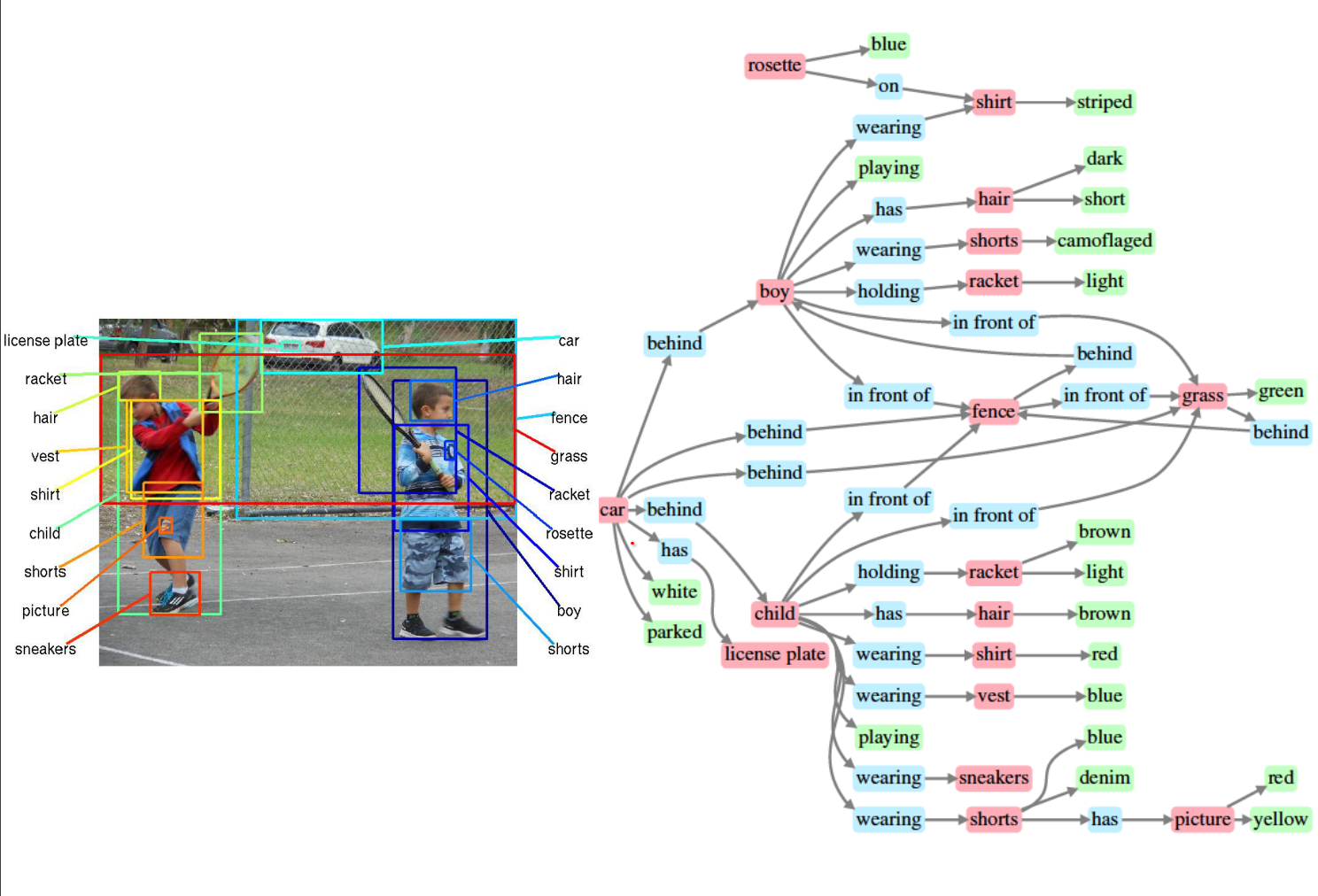
Fei-Fei Li frames vision as the art of telling coherent stories about the world, using human perception as inspiration.

This is the human state.
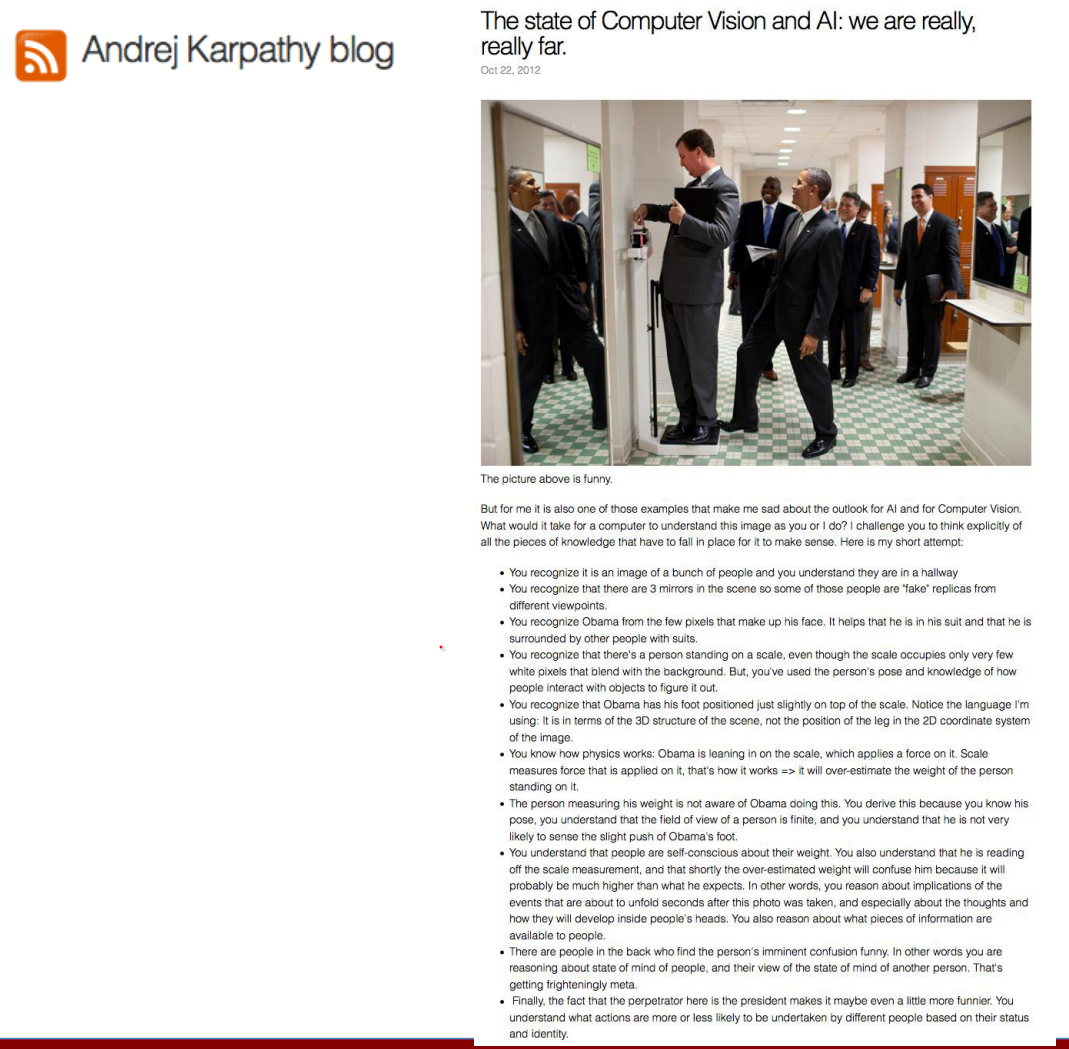
Vision is wonderful.

The course philosophy rests on four pillars:
-
Thorough and detailed: Learn to build, debug, and train convolutional networks from scratch.
-
Practical: Focus on GPU-based training, distributed optimization, and modern tools such as Caffe, Torch, and TensorFlow.
-
State of the art: Study material drawn directly from recent research.
-
Fun: Explore creative applications including image captioning (using RNNs), DeepDream, and Neural Style Transfer.
Prerequisites¶
- Proficiency in Python plus familiarity with C or C++ (assignments use Python and NumPy, while many libraries are written in C++).
- Calculus and linear algebra.
- Background comparable to CS229, including cost functions, derivatives, and gradient-based optimization. A Python tutorial is available on the course website.
Grading and Policies¶
- Three problem sets: 15% each.
- Midterm exam: 15%.
- Final course project: 40% (5% milestone, 35% final write-up, bonus for an exceptional poster presentation).
- Late policy: seven shared late days across problem sets, 25% deduction for each additional late day, and no submissions after three late days per problem set. The policy does not apply to the final project.
- Collaboration policy: read the student code book to understand acceptable collaboration versus academic infractions.
References¶
- Hubel, David H., and Torsten N. Wiesel. "Receptive fields, binocular interaction and functional architecture in the cat's visual cortex." Journal of Physiology 160.1 (1962): 106.
- Roberts, Lawrence Gilman. "Machine Perception of Three-dimensional Solids." Massachusetts Institute of Technology (1963).
- Marr, David. Vision. MIT Press (1982).
- Brooks, Rodney A., Russell Creiner, and Thomas O. Binford. "The ACRONYM model-based vision system." Proceedings of the 6th International Joint Conference on Artificial Intelligence (1979): 105-113.
- Fischler, Martin A., and Robert A. Elschlager. "The representation and matching of pictorial structures." IEEE Transactions on Computers 22.1 (1973): 67-92.
- Lowe, David G. "Three-dimensional object recognition from single two-dimensional images." Artificial Intelligence 31.3 (1987): 355-395.
- Shi, Jianbo, and Jitendra Malik. "Normalized cuts and image segmentation." IEEE Transactions on Pattern Analysis and Machine Intelligence 22.8 (2000): 888-905. [PDF]
- Viola, Paul, and Michael Jones. "Rapid object detection using a boosted cascade of simple features." Proceedings of CVPR (2001). [PDF]
- Lowe, David G. "Distinctive image features from scale-invariant keypoints." International Journal of Computer Vision 60.2 (2004): 91-110. [PDF]
- Lazebnik, Svetlana, Cordelia Schmid, and Jean Ponce. "Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories." Proceedings of CVPR (2006). [PDF]
- Dalal, Navneet, and Bill Triggs. "Histograms of oriented gradients for human detection." Proceedings of CVPR (2005). [PDF]
- Felzenszwalb, Pedro, David McAllester, and Deva Ramanan. "A discriminatively trained, multiscale, deformable part model." Proceedings of CVPR (2008). [PDF]
- Everingham, Mark, et al. "The PASCAL visual object classes (VOC) challenge." International Journal of Computer Vision 88.2 (2010): 303-338. [PDF]
- Deng, Jia, et al. "ImageNet: A large-scale hierarchical image database." Proceedings of CVPR (2009). [PDF]
- Russakovsky, Olga, et al. "ImageNet Large Scale Visual Recognition Challenge." arXiv:1409.0575. [PDF]
- Lin, Yuanqing, et al. "Large-scale image classification: fast feature extraction and SVM training." Proceedings of CVPR (2011). [PDF]
- Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "ImageNet classification with deep convolutional neural networks." Advances in Neural Information Processing Systems (2012). [PDF]
- Szegedy, Christian, et al. "Going deeper with convolutions." arXiv:1409.4842 (2014). [PDF]
- Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv:1409.1556 (2014). [PDF]
- He, Kaiming, et al. "Spatial pyramid pooling in deep convolutional networks for visual recognition." arXiv:1406.4729 (2014). [PDF]
- LeCun, Yann, et al. "Gradient-based learning applied to document recognition." Proceedings of the IEEE 86.11 (1998): 2278-2324. [PDF]
- Fei-Fei, Li, et al. "What do we perceive in a glance of a real-world scene?" Journal of Vision 7.1 (2007): 10. [PDF]